
AWS provides an incredible array of instance type and storage options for HPC workloads. Our previous post discussed the AWS options that System Fabric Works (SFW) chose for Altair AcuSolve™ workloads on Scale-Out Computing for AWS. This entry presents the job turn-around time and price-per-run results found by the SFW study.
SFW decided to use the following configurations for the AcuSolve jobs:
- Impinging Nozzle model, provided by Altair
- c5.18x.large, c5.24xlarge and c5n.18xlarge instance types, all with Elastic Network Adapter
- FSx for Lustre 14400 GB scratch, shared among all cluster nodes
- CentOS Linux 7.6.1810 with HVM
- Intel MPI 2018, bundled with AcuSolve
We then proceeded to benchmark the job turn-around time (performance) and associated price-per-run for different quantities of cores. The goal of this exercise was to determine which job configurations result in the lowest job turn-around time v/s the cheapest price-per-run.
Job Performance
Job performance is defined as the turn-around time for the successful AcuSolve processing of Impinging Nozzle. The following chart plots the turn-around time for executing AcuSolve on the impingingNozzle model on c5.24xlarge, c5n.18xlarge and c5.18xlarge instance types. Due to the different core counts among the three selected instance types, the data points don’t necessarily line up vertically.
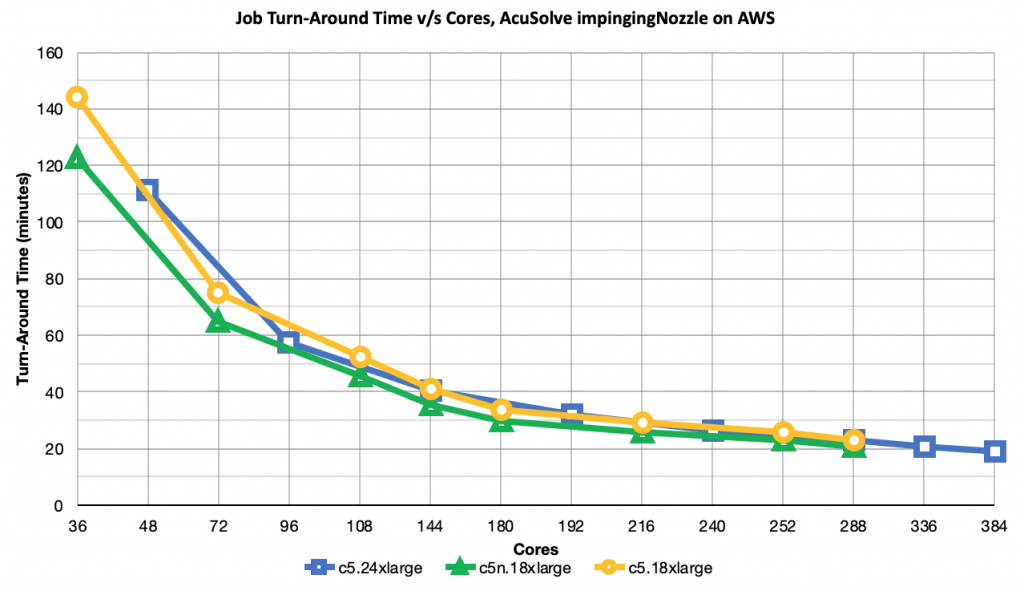
The performance curves for AcuSolve turn-around time follow what is normally expected when demonstrating strong scaling in a distributed system. There is an initial big performance gain and returns begin to diminish as more nodes are added, due to the additional network and MPI overhead.
c5.24xlarge and c5.18xlarge track nearly identically with each other. One important data point to consider is the performance at 144 cores. Here, the performance of both instance types performance is very similar. However, the node count for c5.24xlarge is 3, versus the count of 4 for c5.18xlarge. A lower node count can result in a lower price for the job’s execution, although the higher per-node cost of c5.24xlarge must be taken into consideration.
c5n.18xlarge performs significantly better up to about 144 cores. The performance differential is attributed to the 100Gbps network for this instance type, v/s 25Gbps for the other types. The roughly 15% performance differential of c5n.18xlarge versus c5.18xlarge at 36 cores/1 node is a bit of a mystery. This study’s parameters did not include extensive profiling to determine the “why”, as long as results are consistent across multiple runs. It is likely that the faster 100Gbps network allowed for better performance of the FSx for Lustre scratch filesystem.
SFW did not have access to on-prem performance data for Impinging Nozzle. However, there is anecdotal evidence that the performance on AWS is comparable to that of similar-class on-prem hardware.
Scale-Up and Efficiency
Regarding strong scaling, scale-up is defined as the ratio of base case turn-around time to the turn-around time of a different case utilizing more processors for the same workload. A job that executes in 5m with 2 CPUs, compared against a base case of 10m with 1 CPU, would have a scale-up of 10m/5m = 2. Scale-up may also be represented as a percentage: 2 and 200% are equivalent scale-up values.
Efficiency considers scale-up within the context of how many more processors were used to achieve a particular scale-up. For the previous example, the scale-up of 2 divided by 2x the number of processors = 100%. An efficiency of 100% is ideal, although efficiencies > 100% may occur in some conditions.
The same turn-around time results from Job Performance are considered when computing scale-up and efficiency, using the node count instead of core count on the X-axis. Doing so allows the data points to line up in the chart.
The base case for scale-up of each instance type is 1 node. While the core counts vary between different instance types at a particular node count, the scaling factor (e.g. 2x, 3x) is consistent and directly related to the multiplier of core count per instance type.
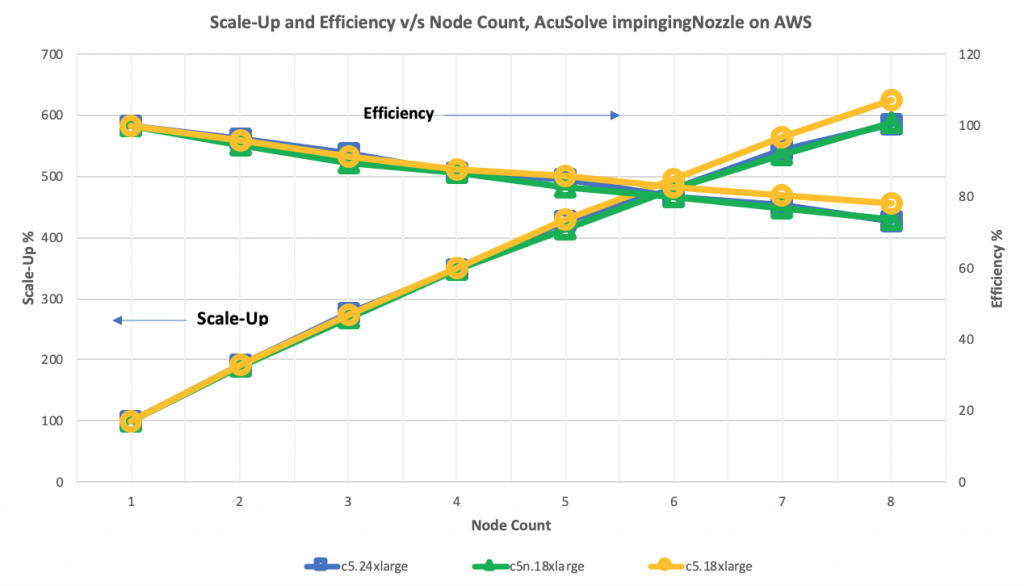
At 2 nodes, the scale-up of ~190% and efficiency of ~95% are consistent for all instance types. Both measures stay roughly consistent until the 5-node count is reached. At that point, scale-up and efficiency begin to drop off for c5.24xlarge and c5n.18xlarge, compared to c5.18xlarge. At 8 nodes, scale-up of 625% for c5.18xlarge is significantly better than ~575% for the other instance types.
Referring back to the turn-around time performance chart, note that there is convergence around 188 cores. That is reflected by the better scale-up of c5.18xlarge, which does not perform as well as the other two types for lower core counts. As the turn-around time performance converges at higher core counts, c5.18xlarge exhibits better scale-up and efficiency.
Scale-up and efficiency are useful metrics for analyzing parallel system performance. While an AWS user is most concerned with the job performance and price, good scale-up efficiency reduces the total EC2 compute cost for jobs that employ more nodes.
Job Price
“Comparative job price-per-run” is the figure used to measure the AWS charges incurred by each job: the “job price”. While there are additional AWS charges associated with the cluster, they do not figure into the comparative job price. The goal is to compare the price-per-run for different job configurations (instance type, node count, storage), not determine a definitive cost.
When estimating AWS charges as a budgetary measure, it would be important to consider charges related to Data Transfer Charges, the cluster’s head node, cluster-wide storage and s3.
To determine the comparative job price-per-run for a particular job, the following calculation may be used:
Pricen = (cn * (tn + sn) * mn / 60
Where:
- Pricen = price for a particular job run n
- cn = node count for job run n
- tn = instance type price-per-hour for job run n
- sn = per-node storage price-per-hour for job run n
- mn = job execution time in minutes for job run n
Instance type price-per-hour may be found on aws.amazon.com. Note that instance type and storage price is determined by the AWS region where the SOCA cluster is instantiated. SOCA also supports the use of the lower-priced Spot Instances for compute nodes, if suitable for an organization’s requirements.
Per-node storage concerns any disk storage that is attached to individual nodes where the cost is incurred per-node. Examples of per-node storage are the EBS root volume and any additional EBS volumes used for scratch.
Each node in this study is configured with a 10GB EBS gp2 root filesystem. The price for each filesystem is $0.10 per GB per month. For purposes of this study, will be considered as $0. Using larger and/or higher-performance io1 volumes on a per-node basis can significantly affect the job cost, so it’s important to take these concerns into consideration when planning the job configuration and determining job price-per-run.
SOCA Makes it Easier
SOCA’s new job accounting features make it much easier to study job price and performance, especially when there are many data points to consider. Every job’s turn-around time and computed job price are stored in ElasticSearch, retrievable in a report format from the integrated Kibana dashboard.
The job accounting feature was not fully available at the time this study was performed.
The following chart plots the comparative job price-per-run against the core count for each job. This data is directly associated with job turn-around time data presented earlier.
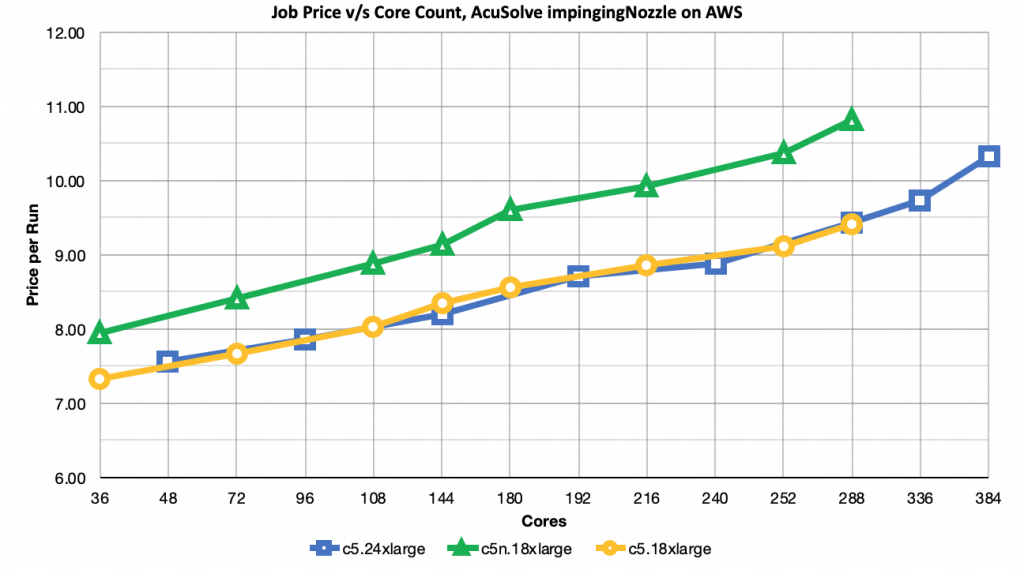
One important takeaway from this chart is that job price scales sub-linearly to the core count for a job. That is, scaling up the number of cores (or nodes) by a factor of N scales the job price by less than N (much less for this data set). This is due to the good scale-up efficiency seen for AcuSolve running on AWS. The jobs execute more quickly at higher core counts, which helps to offset the multiplied per-hour price for the job’s nodes.
The job price for c5.24xlarge and c5.18xlarge is nearly equivalent across core counts when interpolated between data points. The more expensive c5.24xlarge benefits from more cores per node, bringing the job price very close to that of c5.18xlarge. A particular workload might also benefit from the Cascade Lake CPU and higher RAM capacity of c5.24xlarge.
c5n.18xlarge consistently has the highest job-price per run. It also provides the best performance up until about 108 cores, at which point there is very little performance benefit to be gained by paying a higher instance type charge for the 100Gbps network. That may not be the case when using the c5n.18xlarge Elastic Fabric Adapter with AcuSolve, which will be explored in a future study.
Summary
This concludes our three-part series on AcuSolve and SOCA. In summary:
- SOCA provides a cost-effective, turn-key solution for implementing highly scalable HPC clusters on AWS.
- AcuSolve on AWS exhibits good scale-up efficiency (95% at 1 node to worst-case of 74% at 8 nodes in this study), providing sub-linear scaling of job price v/s node count.
- CFD applications such as AcuSolve are most suited to compute-optimized AWS instance types.
- Benchmarking the HPC application across different instance types and core counts are crucial to determine which configurations will provide the appropriate turn-around time and job price.
- AWS and SOCA democratize HPC capabilities, enabling users to take advantage of vast capacity and types of resources with the “pay for what you use” pricing model.
Please contact System Fabric Works if you have any questions or would like to explore implementation of your HPC projects on AWS.