
Our previous post discussed Scale-Out Computing on AWS, a turn-key cluster solution for executing HPC workloads. This entry reports on a System Fabric Works (SFW) study that compares job turn-around time (performance) and job price-per-run for a real-world HPC workload on SOCA.
In determining a real-world HPC workload for our SOCA cluster, SFW turned to Altair AcuSolve™, an industry-leading CFD solver used across a variety of domains, from wind turbine modeling to automotive design. Its primary functions are analysis of fluid flow (dynamics), temperature (heat transfer), and modeling how flow impacts a solid structure. AcuSolve’s processing model is a highly parallel, hybrid OpenMP and MPI design, which is an exact fit for the concept of an HPC workload.
Altair engineering provided SFW with a suitable model for use with AcuSolve, which is considered demonstrative of a real-world scenario with enough cells to exploit strong scaling. Strong scaling is the reduction of turn-around time from the addition of processors to a constant-sized workload.
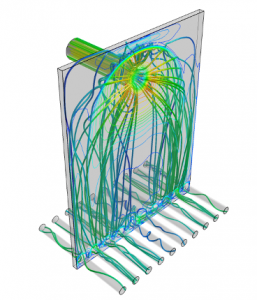
This model is referred to as “Impinging Nozzle”: a simulation of liquid jets, commonly used in production engineering environments as a means of convective cooling. It is a steady, three-dimensional Reynolds-Averaged Navier-Stokes (RANS) simulation of an impinging nozzle, using the robust one-equation Spalart-Allmaras turbulence model, consisting of 7.8 million nodes and 7.7 million elements.
![]()
Compute Node Environment
The operating system chosen for this exercise was CentOS Linux with HVM 7.6.1810 x86_64, provided by AWS Marketplace. CentOS was chosen over RHEL as its use does not incur a charge for the operating system. AmazonLinux2 may have been suitable, but CentOS was chosen as it appeared to be the path of least resistance for the successful execution of AcuSolve.
Altair recommends using Intel MPI 2018 (IMPI) bundled with Altair HyperWorks™ 2019, the application suite which includes AcuSolve.
All MPI operations were executed as shm:tcp over the AWS Elastic Network Adapter (ENA), using the tunings specified in the Altair HyperWorks Advanced Install Guide. A future study will report on AcuSolve performance with the AWS Elastic Fabric Adapter.
Scratch storage was configured on an FSx for Lustre filesystem of 14.4 TB, 2.8 Gbps throughput, shared among all jobs. A study performed today would employ SOCA’s recently added, per-job FSx for Lustre filesystem, as it is allocated on-demand and consistently placed in the same subnet as an associated job’s compute nodes. This configuration avoids Data Transfer Charges and storage charges while at rest.
Long-term storage of the Impinging Nozzle model and job output was provided by the EFS filesystem allocated to the cluster by SOCA.
Instance Type Selection
A primary consideration when deciding what types of AWS EC2 resources to use for a particular workload is the machine instance type. The matrix of instance types documents hundreds of different options, each varying in CPU microarchitecture, core count, amount of RAM, storage capabilities and networking features.
SFW worked with Altair and AWS staff to determine which instance types to include in the AcuSolve benchmarking. The qualifications include:
- AWS Nitro System hardware. Nitro is AWS’ next-generation platform which provides better performance and price compared to earlier AWS platforms.
- High-MHz CPU clock. AcuSolve is compute-intensive and benefits from fast CPUs.
- Large core count. Higher core counts per node reduces the number of nodes required to achieve a particular total core count, improving performance and reducing cost.
- Large amount of RAM. Swapping must be avoided for an HPC workload, which would otherwise impede performance. However, for this model, AcuSolve does not require the very large RAM offered by Memory Optimized
- High-speed networking. AWS instance types offer 10 – 100Gbps networking.
These criteria narrowed the field of instance types to the following Compute Optimized selections:
| Instance Type | CPU MHz | CPU | Cores | RAM GB | Network Gbps | Cost/hr us-east-1 |
| c5.18xlarge | 3.0 GHz | Skylake | 36 | 144 | 25 | 3.060 |
| c5n.18xlarge | 3.0 GHz | Skylake | 36 | 192 | 100 | 3.888 |
| c5.24xlarge | 3.0 GHz | Cascade Lake | 48 | 192 | 25 | 4.080 |
Of the three selected instance types, c5.18xlarge is considered the base model for this study. c5.24xlarge was chosen due to its higher core count per node and newer CPU microarchitecture, to compare job price and performance with fewer nodes at similar total core counts. c5n.18xlarge was chosen to investigate price and performance with the 100 Gbps network versus the 25 Gbps network.
Job Price and Performance
This concludes the discussion of the AcuSolve workload and AWS compute node configuration. In part three of this series, we will take a look at AcuSolve price-per-run and job turn-around time.